카프카 컨슈머
Kafka Consumer는 사용자가 제어하며 poll 메소드를 호출하여 카프카 브로커에서 데이터를 가져올 수 있다. 일반적으로 Consumer의 group.id와 가져올 topic을 지정한다. 같은 group.id를 사용하는 Consumer를 묶어서 Consumer Group이라고 한다.
// KafkaConsumer
... set properties of consumer
val consumer = consumerFactory(props).createConsumer()
consumer.subscribe(listOf("topic-name"))
while (true) {
val records = consumer.poll(Duration.ofMillis(100))
records.forEach {
// processing
}
}
// Spring Kafka
@KafkaListener(
topics = ["topic-name"],
groupId = "group-id",
)
fun subscirbe(
@Payload message: String,
) {
something...
}카프카는 파티션 단위로 데이터를 분배하기 때문에 파티션의 수보다 많은 컨슈머를 그룹에 추가하여 파티션의 수를 컨슈머가 초과하는 경우 특정 컨슈머의 경우 파티션을 할당 받지 못하고 데이터를 처리하지 않는다.
Kafka Rebalance
카프카는 리밸런스를 통해서 컨슈머의 할당된 파티션을 다른 컨슈머로 이동시킨다. 컨슈머 그룹에 새로운 컨슈머가 추가, 제외 되는 경우 그룹내 파티션을 재조정을 한다.
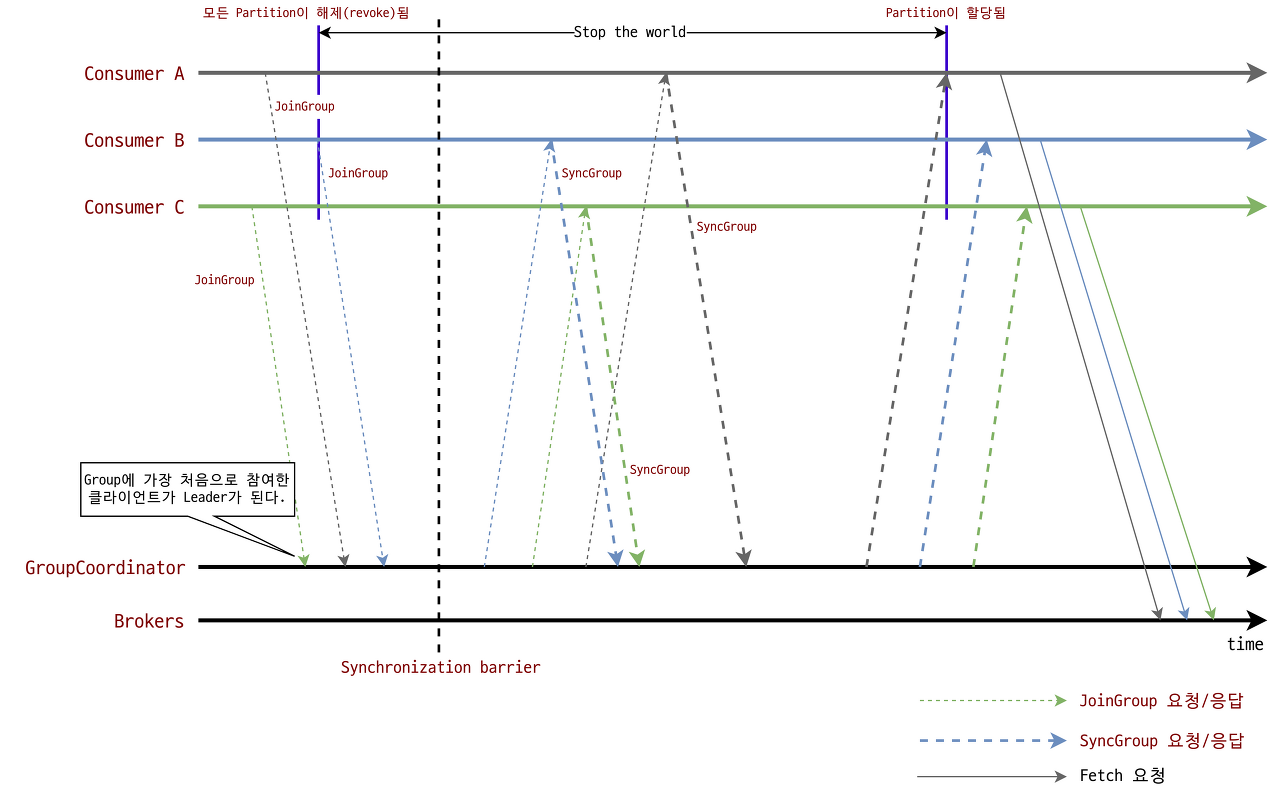
첫번째 단계에서 JoinGroup 요청을 GroupCoordinator로 보내 그룹에 참여한다. 이후 리더로 선정된 컨슈머는 그룹내 파티션을 할당한다.
모든 컨슈머는 Synchronization barrier 전에 메시지 처리를 중지하고 Offset을 커밋 해야 한다.
두번째 단계에서 모든 컨슈머는 SyncGroup 요청을 보내고 리더 컨슈머는 SyncGroup 요청을 보낼때 파티션 할당 결과를 요청에 포함한다. GroupCoordinator는 파티션 할당 결과를 SyncGroup 요청에 응답한다.
오프셋 초기화 과정을 종료후 컨슈머는 브로커의 데이터들을 가져올 수 있다.
컨슈머 리밸런스가 발생하면 각 컨슈머에 할당된 파티션이 해제되므로 재조정 완료 이전까지는 데이터 처리가 일시적으로 중지 된다.
카프카 컨슈머 구성 요소
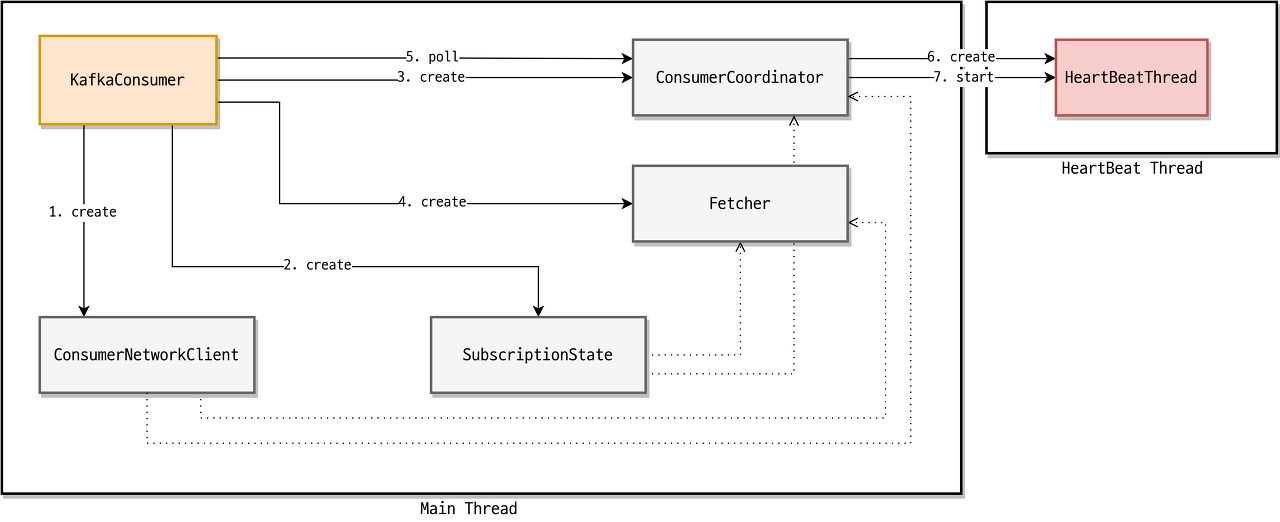
| 구분 | 역할 |
| ConsumerNetworkClient | KafkaConsumer 모든 네트워크 통신을 담당. 모든 요청은 비동기 동작, RequestFuture클래스로 확인 가능 |
| SubsriptionState | 자신이 소비하는 토픽, 파티션, 오프셋 정보를 추적 및 관리 |
| ConsumerCoordinator | 컨슈머 리밸런스, 오프셋 초기화(일부), 오프셋 커밋을 담당 |
| Fetcher | 브로커로부터 데이터를 가져오는 역할 |
| HeartBeatThread | * HeartBeat 시간(Consumer가 중단되진 않았는지 GroupCoordinator가 감시하는 시간) * Polling 간격 시간(브로커로부터 가져온 데이터를 처리하는 시간) 위 두개가 구분되지 않아 Consumer health 여부 해결책(컨슘 시간이 길다면) |
ConsumerCoordinator
ConsumerCoordinator 내부에는 HeartBeatThread가 존재하며 HeartBeatThread는 주기적으로 HeartBeat를 GroupCoordinator에게 전송한다.

- 컨슈머 리밸런스에서는 JoinGroupResponseHandler, SyncGroupResponseHandler 사용
- 오프셋 초기화에서는OffsetFetchResponseHandler 사용
- 오프셋 커밋에서는 OffsetCommitResponseHandler 사용
- HeartBeat 전송에는 HeartBeatResponseHandler 사용
Fetcher
Fetcher는 카프카 브로커부터 데이터를 가져오는 역할을 담당.

- Consumer 리밸런스와 Offset 초기화 과정이 끝나면, KafkaConsumer의 poll() 메소드로 카프카 브로커의 데이터를 가져온다.
- poll() 메소드 호출시 Fetcher의 fetchedRecords() 메소드가 호출 되는데 내부 캐시인 nextInLineRecords와 completedFetched 확인 후 이미 데이터를 가져왔다면 max.poll.records 설정 값만큼 Record를 반환 한다.
브로커에서 가져온 데이터가 없다면 Fetcher의 sendFetches() 메소드를 호출하여 FetchAPI 요청에 대해서 각 브로커에게 보내며 Fetcher가 브로커로부터 응답을 받을 때 까지 대기한다.
브로커로 응답을 받으면 Fetcher의 fetchedRecords() 메소드를 호출하여 반환할 레코드를 가져온다.
| Configuration | Default | Description |
| fetch.max.wait.ms | 500ms | 브로커가 Fetch API 요청을 받았을 때 fetch.min.bytes 값만큼 데이터가 없는 경우 응답을 주기까지 최대로 기다릴 시간이다. |
| fetch.min.bytes | 1bytes | Fetch API 요청이 왔을 때 브로커는 최소한 fetch.min.bytes 값만큼 데이터를 반환해야 한다. 반환할 만큼 데이터가 충분하지 않다면 브로커는 데이터가 누적되길 기다린다. |
| fetch.max.bytes | 52428800 (50MiB) | Fetch API 요청에 대해 브로커가 반환해야 하는 최대 데이터 크기이다. 이 값은 절대적으로 적용되는 값은 아니다. 첫 번째 파티션의 첫 번째 메시지가 이 값보다 크다면 컨슈머가 계속 진행될 수 있도록 데이터가 반환된다. 브로커가 허용하는 최대 메시지 크기는 message.max.bytes와 max.message.bytes를 통해 설정한다. |
| max.partition.fetch.bytes | 1048576 (1MiB) | 브로커가 반환할 파티션당 최대 데이터 크기이다. fetch.max.bytes와 동일하게 첫 번째 파티션의 첫 번째 메시지가 이 값보다 크다면 컨슈머가 계속 진행될 수 있도록 데이터가 반환된다. |
참고
https://kafka.apache.org/documentation/#basic_ops_add_topic
Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org
https://d2.naver.com/helloworld/0974525