Indexing for High Performance
-
Index 는 좋은 성능을 위해서 중요하며 데이터가 점점 커지면 커질수록 더욱 중요해진다.
-
불행하게도, Index 는 종종 잊혀지거나 오해 되어 잘못 사용 될 수 있고 이는 현실 세계에서 문제가 된다.
(저자 : 그래서 우리가 query optimzation 보다 앞 챕터로 넣은 것이다.)
-
인덱스 최적화는 쿼리 최적화를 위한 가장 강력한 방법이다.
-
진실된 인덱스 작업은 너의 쿼리 재작성을 요구할 수 있다. 따라서 쿼리 최적화보다 먼저 배워랑
Indexing Basics
MySQL에서 storage engine 비슷한 방법으로 인덱스를 사용한다.
storage engine은 인덱스 자료 구조에서 값을 찾는다.
값을 매칭 되는 것을 찾을 때, storage engine은 row를 찾을 수 있다.
mysql> SELECT first_name FROM sakila.actor WHERE actor_id = 5;
(actor_id -> index)
1. MySQL은 인덱스를 사용해 (actor_id == 5) 를 찾을 것이다.
Index는 테이블에서 하나 이상의 컬럼을 포함할 수 있다.
만약, 너가 하나 이상의 컬럼에 인덱스를 걸고 있다면? 컬럼 순서는 매우 중요하다.
왜냐면, MySQL은 인덱스의 가장 왼쪽 부터 효율적으로 검색을 하기 때문이다.
또, 두개의 컬럼에 대해서 한번에 인덱스를 거는 것과 하나씩 두개로 인덱스를 나눠 거는 것은 다르다.
Types of Indexs
-
인덱스는 목적에 다라 디자인 되어진 여러가지로 유형이 있다.
-
인덱스는 서버단이 아니라 storage engine 단에서 구현 된다.
-
따라서, 표준화가 안되어 있으며 엔진마다 조금씩 다르게 작동하며, 제공되는 유형이 다를 수 있다.
-
B-Tree indexes
-
사람들이 유형을 말하지 않고 인덱스를 말한다면, 보통 B-Tree index 이다.
-
대다수의 storage engine은 이 유형을 제공 한다.
(5.1 버전 전까지는 AUTO_INCREMENT 컬럼을 인덱스 했다면? Archive engine 은 제공하지 않았다)
-
Storage engine들은 B-Tree index를 다양한 방법으로 사용하는데,
MyISAM은 prefix 압축 기술로 인덱스를 작게 만들고, InnoDB는 그대로 나둔다.
MYISAM은 물리적 저장 장소에서 인덱싱 된 row를 찾고,
InnoDB는 primary key value로 찾는다.
(InnoDB는 B+Tree를 사용한다는데 뭔소리야??)
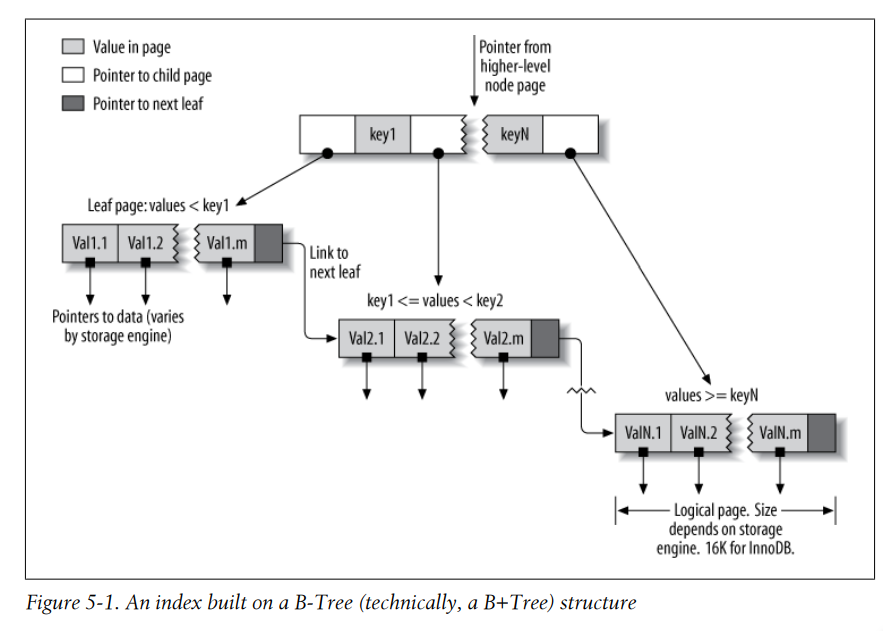
-
B-Tree는 storage engine이 데이터를 찾기 위해 전체 테이블을 스캔하지 않기 때문에 속도가 빠르다.
대신, (그림 참조) 루트 노드가 자식 노드에 pointer를 잡고 storage engine은 이 pointer를 따라간다.
이 작업으로 원하는 값이 있는 node page에서 원하는 pointer를 찾을 수 있다.
결국, storage engine은 원하는 값이 leaf page에서 없는지? 있다면? leaf page에 도달했는지 결정만 하면 된다.

-
Leaf Page는 other page에 대해 pointer가 아니라 인덱싱 data에 pointer를 갖는 점에서 특별하다.
-
그림에서는 하나의 노드 페이지와 그것의 leaf page를 보여주는데 실제로 더 많을 수 있다.
-
Tree의 depth는 테이블 사이즈에 따른다.
-
대부분의 stroage engine은 임의의 순서대로 record 하지만(B-Tree), inno db 는 클러스터되어 기본적으로 주키의 순서대로 정렬되어서 저장(B+Tree).
Benefits of Indexes
-
인덱스가 성능을 향상 시킨다고는 하지만 항상 그런 것은 아니니 주의해라.
-
MySQL은 ORDER BY 나 GROUP BY 명령어 사용시에 미리 정렬된 점을 이용할 수 있다.
-
value 복사본을 저장함으로 어떤 쿼리에 대해서는 index 한개로 처리가 가능할 수 있다.
-
주요 장점
-
데이터를 찾기위한 부담을 줄여준다.
-
서버가 정렬하는 것과 임시 테이블 작성을 피하는 것을 도와준다.
-
random I/O에서 sequential I/O 로 변환해준다.
인덱스가 항상 최선의 해결책인가?
그렇지는 않다.
High 레벨에서 storage engine이 추가 작업 없이 row를 찾는 것을 도와줄 때 인덱스는 가장 효과적이다.
작은 테이블에서, 테이블 전체를 읽는데 효과적이다.
중간 테이블에서, 매우 효과적이다.
큰 테이블에서, 인덱스를 사용하기 위해서 작업이 필요하다. 그러한 경우, 너는 쿼리에 적합한 개별 row가 아니라 row group을 찾는 기술을 선택해야 한다. (예를 들어, partitioning!)
만약 테이블 개수가 많다면, 쿼리를 위한 몇가지 문자를 저장하기 위한 metadata table을 만들는 것도 좋다.
(그러니까 정규화를 잘 하라라는 말이야)
190 페이지